402174: GYM100685 K Key to Magica's diary
Description
He's smart, he's rich — and he needs your help. Scrooge McDuck's Number One Dime is stolen by Magica De Spell. Best Scotland Yard inspectors are working on this case but the only evidence they found is Magica's accidentally dropped secret diary. Unfortunately, it is protected by some spell that prevents everybody from understanding its contents. That's why they need you - the best mathematician of Duckburg. The first thing you noticed is that some words are occurring much more often than others and form some weird pattern. You've made a hypothesis that these words are part of Magica's spell and decided to ignore them for future analysis. After that it became pretty obvious that some words in the diary are found next to each other quite often (such as 'Scrooge' and 'McDuck') while others will be located pretty much independent from each other. You believe that this is the key to Magica's diary and want to check your idea.
More precisely, word is a non-empty continuous sequence of English letters. Text may contain other symbols, you should consider them as spaces. Words are considered to be case-insensitive. Define P(a) as percentage of word a in the text (i.e. the number of a occurrences divided by the total number of words in the text). Similarly, you define P(a, b) as the rate of words a and b occurrences adjacent to each other (i.e. number of such occurrences divided by total number of adjacent word pairs in the text). Then
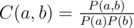
You are particularly interested in some pairs of words and want to check how dependent they are. Unfortunately, the diary is too large to do this analysis manually, so you decided to write a program to do that for you.
InputFirst line of input contains one integer number N — the total number of lines in Magica's diary (1 ≤ N ≤ 4000). Then N lines of text follow. Diary contains only English letters, brackets, punctuation marks (0123456789.,:;-!?'()"), ampersands and spaces. The total length of the text is less or equal than 500KiB, and the length of each word is not more than 20. The text also contains more than one non-magic word. N + 2nd line contains K — the total number of 'magic' words that should be ignored (0 ≤ K ≤ 100). Next K lines contain these words, one per line, lowercase. N + K + 3rd line contains Q — the total number of word pairs you're interested in (0 ≤ Q ≤ 50 000). Then Q lines follow, each containing two lowercase words.
OutputFor each query (a, b) you should output the value of C(a, b) as a floating point number on the separate line with absolute or relative precision of 10 - 6.
ExamplesInput3Output
I have lived through
some terrible things in my life,
some of which actually happened.
3
of
in
which
3
some actually
things life
lived through
6.545454545454546Input
0.0
13.090909090909092
1Output
(2 - 2) Plus (1 - 1) equals 0
0
1
equals plus
4.0